I invested a bit of time to understand the different type of AI models available, mostly LLM or MLLM, and used Ollama to run these, also got RAG powering them and built an Agent after that. Absolutely loved it!
First I did the machine set-up with Ubuntu, given this is the leading distro related to AI, and then got Nvidia drivers and CUDA toolkit installed to get my LLMs to fire up. I could have used LM studio but I wanted flexibility and the use the of command line so chose Ollama instead.
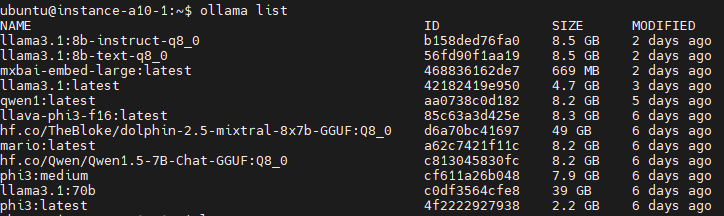
After that, I downloaded the GGUF models files from Huggingface on my A10 machine, started to infer and tried to grasp a bit of the behaviour and differences among them. Computer wise I could not get anything better than an A10 so I struggled to run anything bigger than 10B parameter model. For instance llama3.1 70b was ridiculously sluggish and made my set-up crash. I mostly enjoyed the 7 or 8 billion parameters models, and also trying the different quantisation marks to get a faster inference and see impact on output quality.
Then my favorite: I was really blown away by RAG, the retrieval augmented generation feature. I discovered that you need to use embedding models in addition to the vector database to make it work and the process can take a bit of time but dear, RAG is good!
I have to admit llama3.1 8b (small compared to the 70b and 320b ones) was truly excellent combined with RAG; I was surprised because I had low expectations compared to the bigger models I am (we are?) used to infer on on the internet… but it gave me tremendous results and made me realise that it could dramatically increase my productivity. Thing is, if I wanted to use it for real, I would have to think carefully on where to run it and how to store my documents and do both things securely, and unfortunately I think some cloud computing costs would be inevitable. If only I had the courage to set-up the habit of uploading all the documents I find useful into a vector database I would end up with a super assistant! I found it so useful that I went a bit deeper on this topic, looked at indexing, parsing and tested different chunk sizes and chunk overlap.
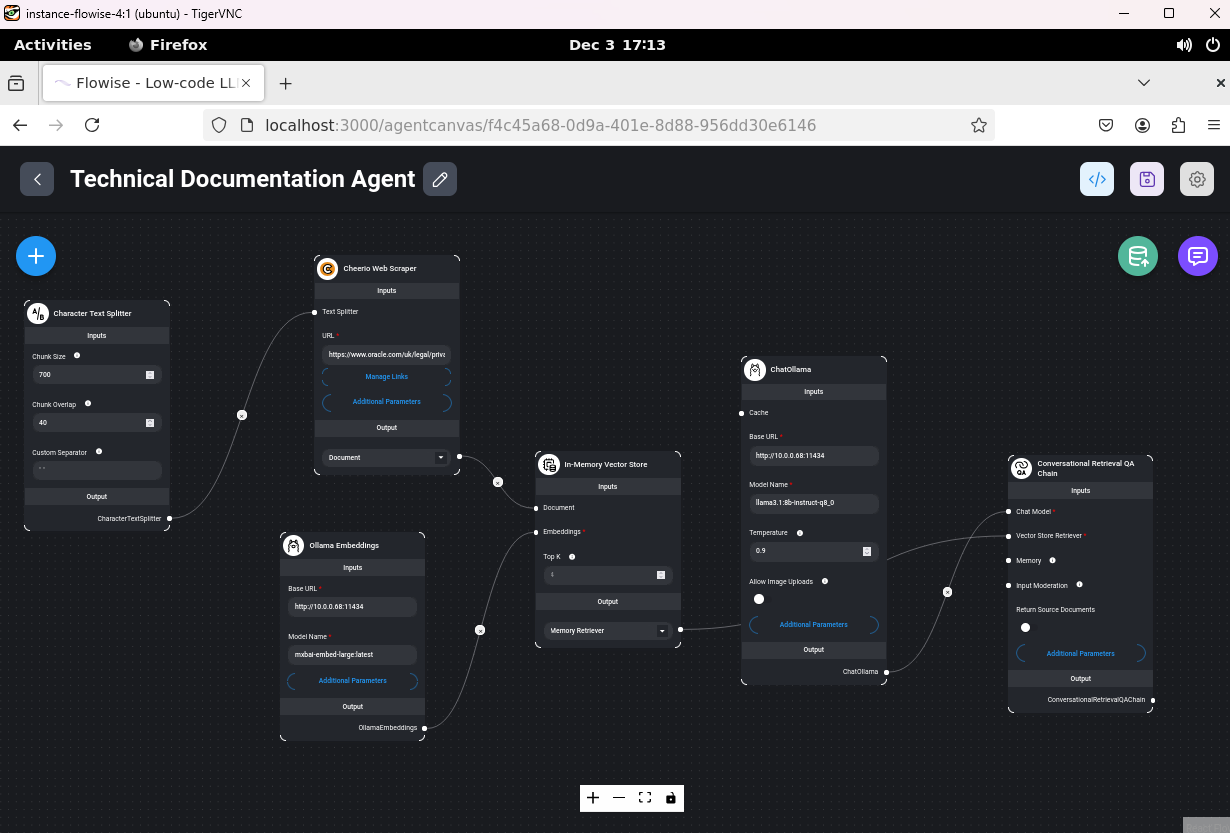
Finally I used a LLM agent builder, in this instance it is a low code application called Flowise that help a user to graphically combine multiple AIs and to orchestrate function calling i.e an LLM can use a calculator, or scrape a website, or call another LLM that is super specialised in one area, or whatever other thing. It was useful for me to understand the concept of “agent” in this fashion, with the use of “workers” and “supervisor”. Sounds like we can automate a few things with these and this may change the way we interact with applications in a way, please see below.
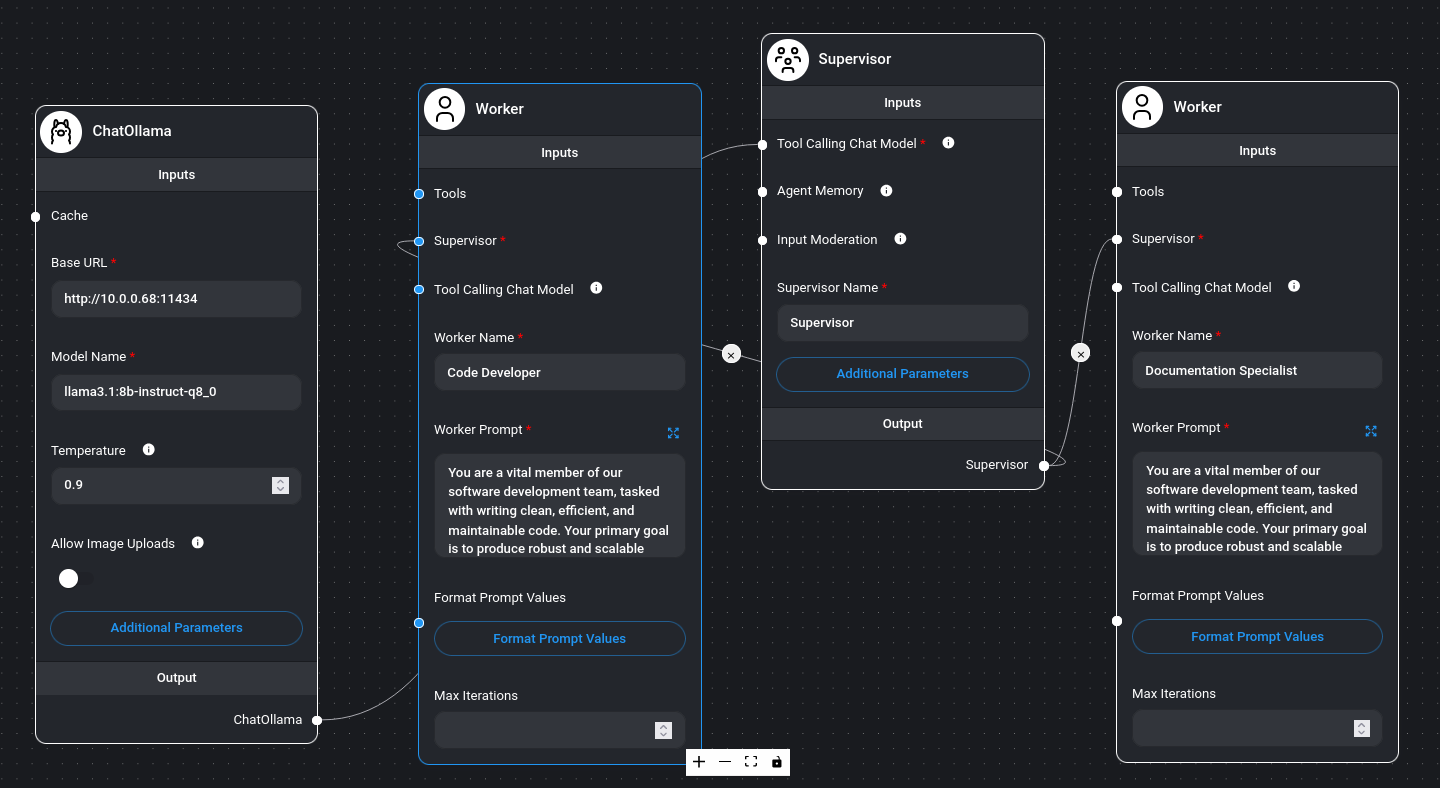
Overall, I had a blast and a lot of learnings gathered in this instance: I found the uncensored dolphin models hilarious and I really recommend you give it a shot, also loved the RAG results and how massively useful it is, and just began appreciating the power of the agents to chain different AI together to work towards an end result in a combo fashion.
Your passion for exploring and understanding the benefits of cutting-edge technologies is truly inspiring. Thank you for sharing your experiences and insights!